Ejabber 压力测试
1.测试环境
– 服务端:普通机*(I3 2核心4线程)/mem:16GB
– 客户端:普通机*(I3 2核心4线程)/mem:48GB(4台)
– 系统:sys:Centos 6 Erlang:OTP 18 Ejabberd 15
– 网络:内网千兆互联
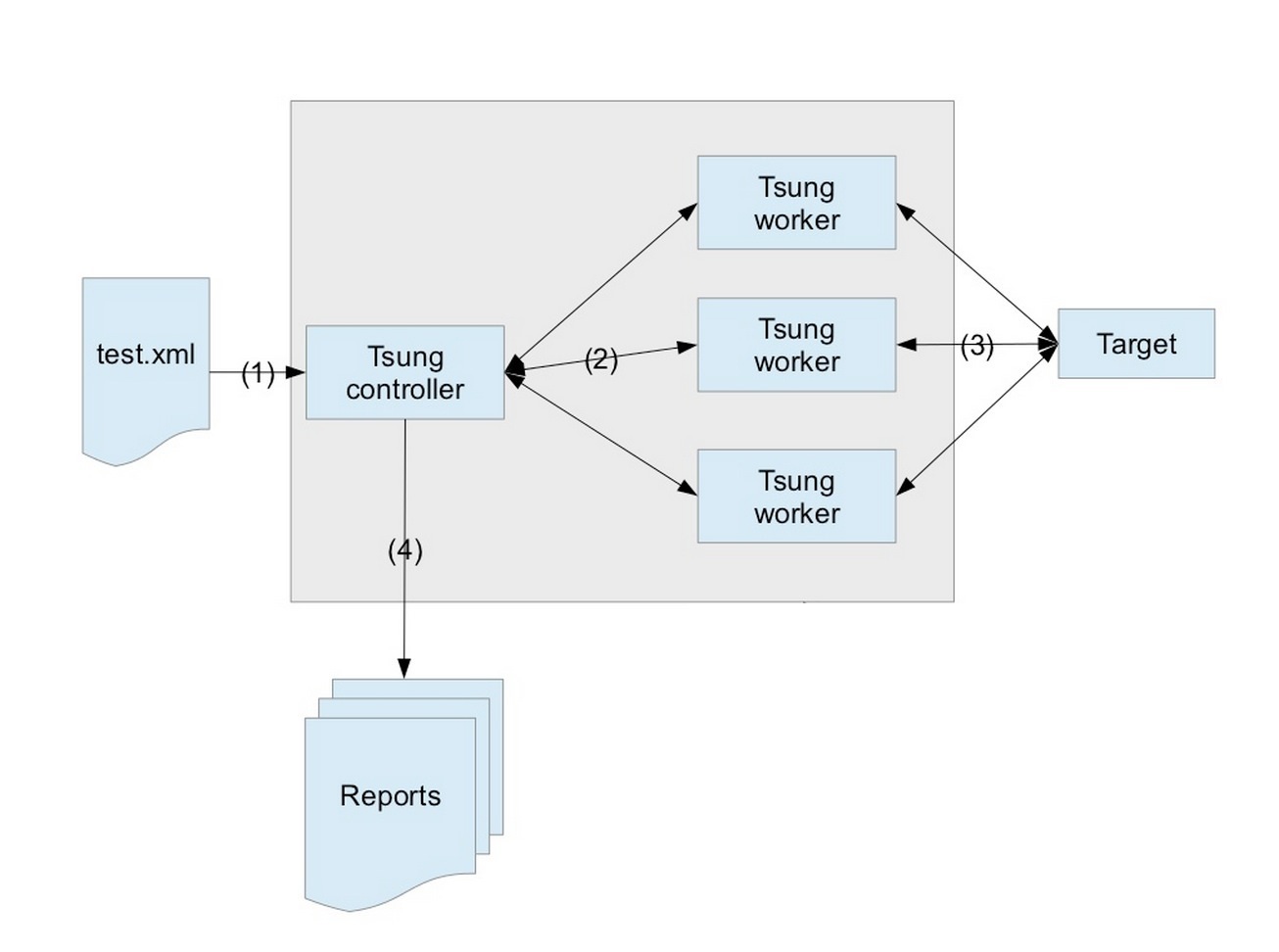
分布式测试
2.Ejabberd 性能调优
调整ulimit限制
编辑/etc/security/limits.conf,加上:
# 方便看core root hard core unlimited root soft core unlimited root hard fsize unlimited root soft fsize unlimited # socket连接数限制 root hard nofile 655350 root soft nofile 655350
编译优化
官方不建议开启Hipe,速度提升的同时可能带来一些问题,如fprof不能正常使用,这里面选择部分hipe(xml),参考Speed Up Ejabberd
cd ejabberd/deps/p1_xml/src erlc +native xml.erl cp xml.beam ejabberd ebin
启动参数调整(安装路径默认)
编辑/etc/ejabberd/ejabberdctl.cfg
- ERL_MAX_PORTS (默认最大32w在线)
每个到客户端(s2c)和服务器(s2s)的连接消耗一个port, ERL_MAX_PORTS定义了Ejabberd可以支持的并发连接数,默认值为32000,大并发连接场景下的应用需要增大该参数的值。这里改成3200000。
ERL_MAX_PORTS=3200000
- ERL_PROCESSES (默认最大12w在线)
Erlang消耗很多轻量级进程, 如果Ejabberd比较繁忙, 可能会达到进程数上限, 这种情况会导致高。 当消息延迟过高时, 需要判断是否是由于该参数引起的。默认值为250000,这里改成25000000。
ERL_PROCESSES=25000000
- Mnesia表过载
大并发时mnesia警告** WARNING ** Mnesia is overloaded: {dump_log, write_threshold},在disc_copy类型的表时,有两个参数影响出现Mnesia is overloaded: {dump_log, write_threshold}错误,默认参数是dump_log_write_threshold 50000 -mnesia dc_dump_limit 40。
dc_dump_limit:磁盘备份表从内存中被抛弃的时间间隔
dump_log_time_threshold:在新垃圾回收之前的最大的写入数
MNESIA_OPTIONS="-mnesia dump_log_write_threshold 50000 -mnesia dc_dump_limit 40"
- ETS表个数限制问题
ets表使用的数目超过系统的限制提示:”Too many db tables”
ERL_MAX_ETS_TABLES=140000
- 快速垃圾回收(影响不确定,不是很建议加)
按1k/sec 频率登录时,当在线到达10w时会触发gc(Major collection),在gc执行期间开销比较大(通过VTune),会引起中断,造成cpu跑满,系统响应下降。fullsweep_after控制深扫描的频率,这个参数确定多少次gc后执行一次深度gc,这里调成0,可以较快内存回收。
ERL_FULLSWEEP_AFTER=0 export ERL_FULLSWEEP_AFTER
- Erlang 虚拟机参数(影响不确定,不是很建议加)
参考:http://www.cnblogs.com/lulu/p/4132278.html
修改/etc/ejabberd/ejabberdctl.cfg中的ERL_OPTIONS
ERL_OPTIONS="-sbt db -sbwt none -swt low"
+sbt db 绑定调度器与CPU的亲缘性
+sbwt none 关闭beam 调度器 spinlock,降低CPU
+swt low 提高调度器唤醒灵敏度,避免长时间运行睡死问题
+P 2000000 进程数限制(默认即可)
+K true 启用epoll (默认使用)
+smp auto 在多核上开启多个调度器 (默认使用)
ejabberd配制调整
- 调整日志等级
修改/etc/ejabberd/ejabberd.yml
loglevel: 3
- 堆大小监视调整
在线到达10w后cpu消耗大问题。
watchdog_large_heap: 10000000
内核参数调整
net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_tw_recycle = 0 net.ipv4.tcp_timestamps = 1 net.ipv4.tcp_max_syn_backlog = 65535 net.ipv4.tcp_fin_timeout = 30 net.ipv4.tcp_rmem = 4096 4096 16777216 net.ipv4.tcp_wmem = 4096 4096 16777216 net.ipv4.ip_local_port_range = 1025 65000 fs.file-max = 65535000 net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216 net.core.netdev_max_backlog = 30000 net.ipv4.tcp_mtu_probing = 1
3.压测场景
- 2k/s 登陆、认证、操作。
- 运行2分钟后20w在线
4.结果
- 4台tsung集群未跑满,瓶颈在服务器。
- 服务器:未触发gc时CPU剩余30%左右。
- 服务器:内存最高7g,登陆完后稳定3g。
- 服务器:流量上平均收2.5m/sec,发3.5m/sec。
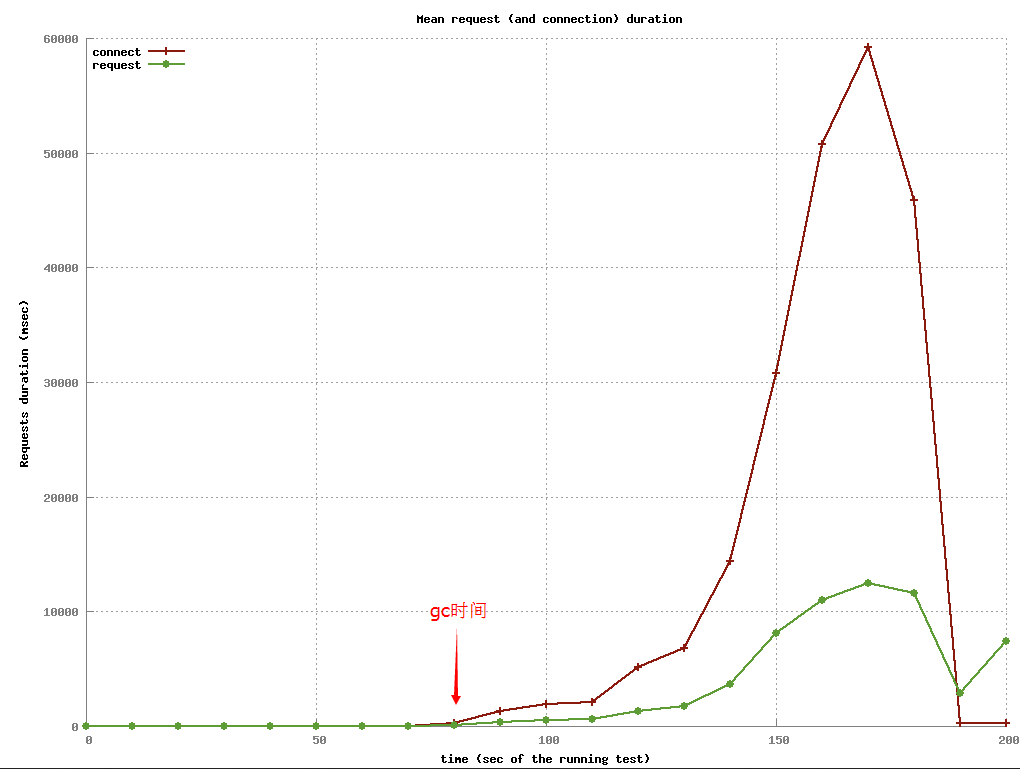
- 在gc(Major collection)启动时会比较严重影响服务器响应速度,在不开启快速回收(fullsweep_after)在线达不到要求(20w),下图可以明显看到。
参考资料
1.Erlang C1500K长连接推送服务-性能
http://www.cnblogs.com/lulu/p/4132278.html
2.Erlang进程堆垃圾回收机制
http://blog.csdn.net/mycwq/article/details/26613275
3.Erlang垃圾回收机制
http://www.cnblogs.com/me-sa/archive/2011/11/13/erlang0014.html
4.erlang 虚机CPU 占用高排查